
After a very long time I seem Tim Berglund speaking. Its always refreshing to understand distributed system explained in simple terms.
The what and why of GraphQL
What?
GraphQL is a query language for APIs that allows us to write queries that define the data that we receive. But why do we need one more layer? The answer to this question lies in understanding the problem that we face once our API starts evolving. As our API evolves we add/remove new parameters and it gets consumed by different clients.
Why?
We can understand GraphQL by an analogy, first, let’s try to understand what is the purpose of SQL, SQL is a structured query language to access data from the database. If we compare REST endpoint to be a data source(aka table) then the endpoint is like a source of all the information in the resource. But there is no similar technology to query the API.
Let’s try to understand this by an example, assume that there is an API that exposes customer information.
Each customer has an order and each order has multiple line items. If we want to display order details for a customer, we need to make a call to get all orders, and then for each order, we need to make a call to get order details and for each order detail, we need to make a call to fetch line item. This is a lot of calls just to display order details.
GraphQL can provide a solution where we can query this information in a single call and its responsibility of the GraphQL server to make other calls and combine these. This will save lots of network calls.
On top of this GraphQL solves the following problems:-
Cluttered API: Every API starts clean but as it evolves, new parameters are added which is required for all clients. So effectively the client needs to fetch the details even if it’s not going to be used. This creates problem considering the wastage of network bandwidth.
Dumb endpoint: Traditional API does not have the capability to provide aggregate functionality. The endpoint has a very limited capability to store or retrieve information in different criteria.
Under fetching: It means not getting enough information in a single call and forces the client to make further calls to get full information.
Over fetching: It defines a situation where an API client fetches too much information that is not required.
Aggregator: This maps to the backend for the front end pattern. If we have multiple endpoints it becomes the responsibility of the client to aggregate these API for a single-use case.
No Contract: And last but not least is there is no intelligent contract between backend and front end to talk.
In next section, I will explain how GraphQL solves these problems with examples.
Source Code: https://bitbucket.org/krvivek007/graphql/src/master/
Posted in Uncategorized
Hibernate configuration to analyse query
Last day I was working on an application to increase its performance. I found 3 configurations that helped me to analyse query and get rid of unwanted queries.
hibernate.show_sql: true | false
hibernate.format_sql: true | false
Above two parameter can be configured to to display the hibernate queries. To my utter surprise even a simple application makes so many queries.
hibernate.generate_statistics : true|false this displays the hibernate statistics
Session Metrics {
0 nanoseconds spent acquiring 0 JDBC connections;
0 nanoseconds spent releasing 0 JDBC connections;
0 nanoseconds spent preparing 0 JDBC statements;
0 nanoseconds spent executing 0 JDBC statements;
0 nanoseconds spent executing 0 JDBC batches;
0 nanoseconds spent performing 0 L2C puts;
0 nanoseconds spent performing 0 L2C hits;
0 nanoseconds spent performing 0 L2C misses;
nanoseconds spent executing 0 flushes (flushing a total of 0 entities and 0 collections);
0 nanoseconds spent executing 0 partial-flushes (flushing a total of 0 entities and 0 collections)
This gives the details about all the activity in executing a query.
Both of these information can be used to tweak query and configuration to optimize hibernate performance.
Posted in Uncategorized
Redis – really a swiss army knife
I am exploring redis and its many capabilities and really blown away by the different ways we can use it to solve scalability problem. other than using it as a fast read/write data store it can be used and message oriented middle ware(aka pub/sub mode) and a streaming platform(like Kafka).
Here are couple of article about its pub/sub and streaming capabiliites.
- Redis Spring Boot Pub/Sub example https://www.baeldung.com/spring-data-redis-pub-sub
- Problem in scaling redis pub sub in cluster mode:https://www.youtube.com/watch?v=6G22a5Iooqk
- Event drive java application with redis: https://www.youtube.com/watch?v=Gmwh-tUr_1E
Its really a swiss army knive!
Posted in Uncategorized
DBeaver Analysing Query
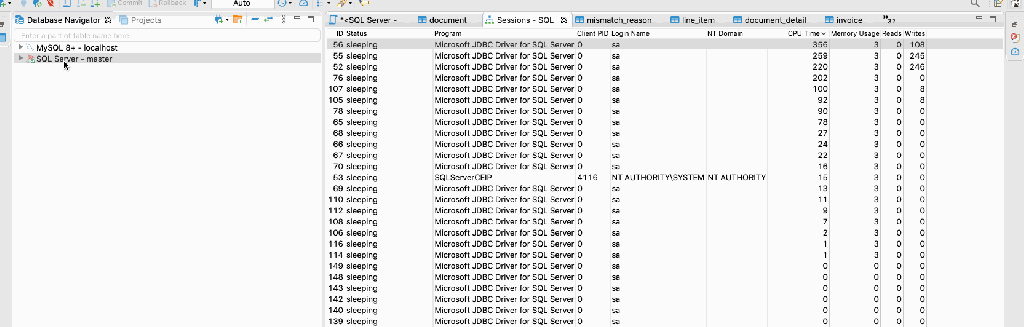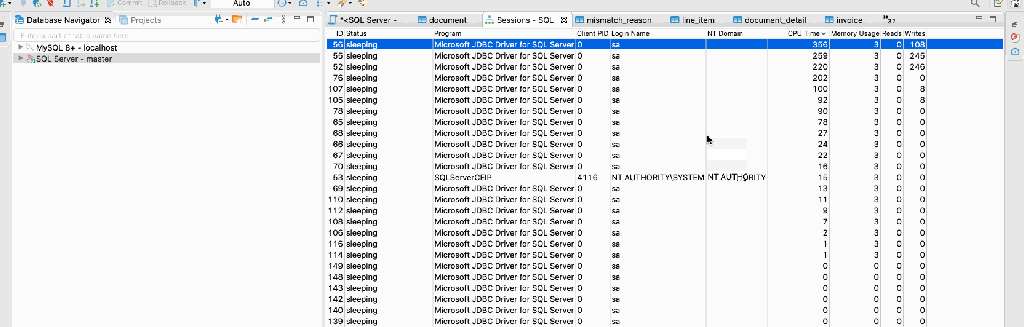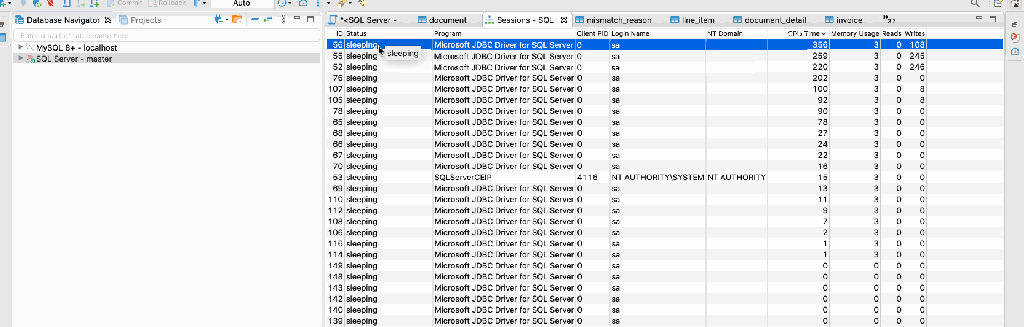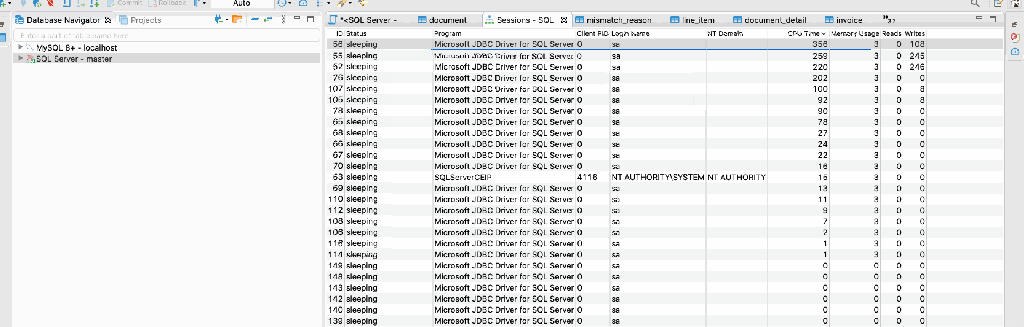
Last week we were working a project where we need to analyze some query and found an interesting way to check it. We were DBeaver DB client. It has a nice feature where you can check the query parameter.
Below screencast displays how to find the expensive query.
Posted in Uncategorized
Spring Quartz – Running many JOB at same instance
Last week I was working on a project where I need to schedule same Jobs for multiple clients at different time interval. I crated a Job class and scheduled it at different cron expression. But to my surprise when I triggered two job at same time only one of them get executed and to make it worse it was random. Sometime, job 1 gets executed sometime job2 get executed. Then after a lot of debugging i found that quartz fire an event and how many jobs can be executed for that even is determined by a parameter org.quartz.scheduler.batchTriggerAcquisitionMaxCount This tell that how many jobs can be scheduled when its triggered at same instance.
Posted in Uncategorized
vert.x
I get never enough of vert.x, everything I watch this video it feels new.
Repository: https://bitbucket.org/krvivek007/vertxcluster-sender/src/master/
https://bitbucket.org/krvivek007/vertxcluster-receiver/src/master/
Posted in Uncategorized
Behavior Trait of an Engineer
I read an article almost 10 years back that describes the behavior of an engineer. At that time I was very impressed because it really explained my behavior. Last Friday when we were discussing why an engineer behaves like that I realized that most of the point that we discussed is answered in that article. After much effort and searching, I found that at https://www.cmrr.umn.edu/~strupp/engr.html
Posted in Uncategorized
chocolatey rocks!
Its quite a long time since i opened my Windows machine and started setting up development environment. I was about to install all software then I realised that there is a fantastic package manager for Windows called chocolatey. It makes life much simpler. Simply run command like Linux and install the packages.
Posted in Uncategorized
Reactive System
The concept of a reactive system has always fascinated me. How to design a system which can be resilient at the core with varying load and remain fault tolerant. I started exploring it with this course. When I started this course this seems like a black magic but as I keep exploring more and more this started making sense. Especially after going through below presentation.

Posted in Uncategorized
